While the ImageNet dataset has been driving computer vision research over the past decade, significant label noise and ambiguity have made top-1 accuracy an insufficient measure of further progress. To address this, new label-sets and evaluation protocols have been proposed for ImageNet showing that state-of-the-art models already achieve over 95% accuracy and shifting the focus on investigating why the remaining errors persist.
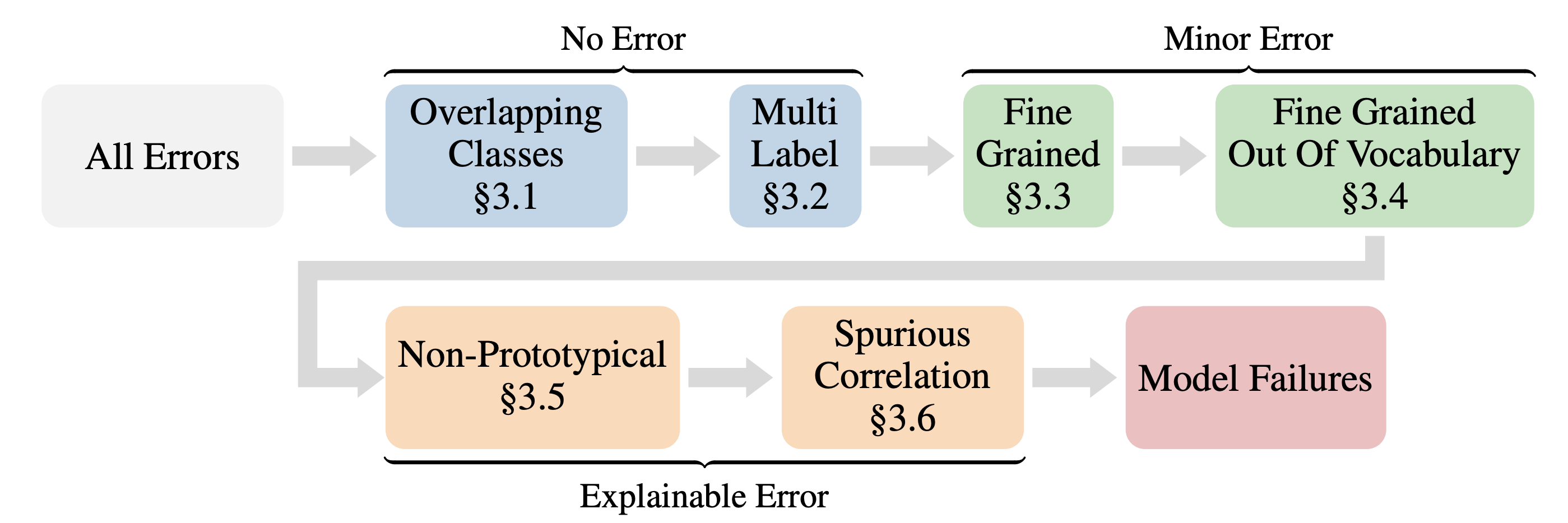
Recent work in this direction employed a panel of experts to manually categorize all remaining classification errors for two selected models. However, this process is time-consuming, prone to inconsistencies, and requires trained experts, making it unsuitable for regular model evaluation thus limiting its utility. To overcome these limitations, we propose the first automated error classification framework, a valuable tool to study how modeling choices affect error distributions. We use our framework to comprehensively evaluate the error distribution of over 900 models. Perhaps surprisingly, we find that across model architectures, scales, and pre-training corpora, top-1 accuracy is a strong predictor for the portion of all error types. In particular, we observe that the portion of severe errors drops significantly with top-1 accuracy indicating that, while it underreports a model’s true performance, it remains a valuable performance metric.
We release all our code at https://github.com/eth-sri/automated-error-analysis.
@inproceedings{ PeychevMFV2023, title={Automated Classification of Model Errors on ImageNet}, author={Momchil Peychev and Mark Niklas M{\"{u}}ller and Marc Fischer and Martin T. Vechev}, booktitle={Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS)}, year={2023}, url={https://openreview.net/forum?id=zEoP4vzFKy} }